2023年,人工智能界7大可能事件,7大发展方向预测
时间:2023-01-25 15:02:31 热度:37.1℃ 作者:网络
美国作家卢克 · 多梅尔曾在《人工智能》一书中提出 " 奇点 " 的概念,奇点指的是机器在智能方面超过人类的那个点。目前,人工智能在技术和产业两个方面临近 " 奇点时刻 "。第一,信息革命正从技术深化到科学,向智能方向提升,人工智能正处在科技革命的奇点上。第二,信息革命正从科学转化为技术,向智慧产业深化,人工智能正处在产业革命的奇点上。
人工智能发展出现突飞猛进现象,认为奇点到来,主要有三个标志:
1、形成了国际人工智能三大巨头,DeepMind,OpenAI,FAIR均在基础领域,算法等方面取得关键性进步。相比,国内的华为,腾讯,阿里,百度这些企业在人工智能领域,与这三大巨头相比,差距极大。
2、新的算法和大模型出现,极大程度提高了机器智能水平。最近几年Transformer与扩散模型的出现,极大将机器智能提升了几个数量级。
3、人工智能越来越便宜了。人工智能过去靠大数据,海量的算力支持,使得实际应用时成本高昂,只能在小范围内使用。如今新的算法出现,对大数据的依赖度下降,新的算法也极大节约了算力,使得人工智能的广泛应用成为可能。
那么,2023年,人工智能会期待哪些新突破呢?这些突破同样也可能会影响到医疗健康领域。
1、OpenAI将发布 GPT-4,GPT-4将更加震撼人类!基于GPT-3的chatGPT-3已经通过图灵测试,轻松过了美国执业医师考试的关,同样还能写论文,回答问题,几乎无事不能。让微软狠心投入100亿美元,获得独占权!
GPT-4是OpenAI的新一代生成语言模型,它有着强大的功能,最近到处流传着它的消息。GPT-4预计将在2023年年初发布,相较于GPT-3和3.5,GPT-4的性能有着跳跃式的提升。尽管最近有关ChatGPT的讨论正在火热朝天地进行,但相比GPT-4,这只是前奏而已,让我们拭目以待!
当今大多数主要语言模型都是在约3000亿个token的数据语料库上训练的,比如说OpenAI的GPT-3(1750 亿个参数)、AI21 Labs的Jurassic(1780 亿个参数)和微软/英伟达的Megatron-Turing(5700 亿个参数)。
有人预测,GPT-4的数据集要比上面提到的大一个数量级,也就是说它可能在10万亿个token的数据集上进行训练。同时它的参数将比Megatron-Turing的要少。如下图:
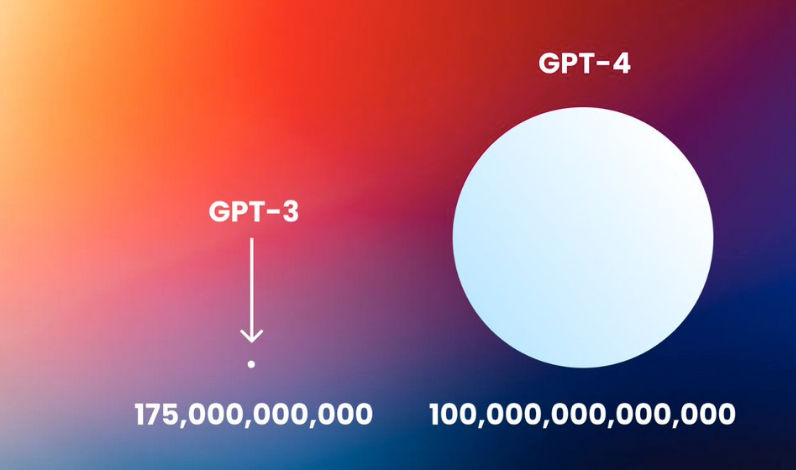
前者是1750亿个参数,而后者则十万亿级参数!!几乎是爆炸式增长。虽然现在还没有最终确认,但是可以相信,未来几年,大参数模型可能会穷尽人类所有语言的排列组合形式。
据说,GPT-4有可能是多模态的,除文本生成之外,它还可以生成图片、视频以及其他数据类型的输入。这意味着GPT-4能够像DALL-E一样根据输入的文本提示词(prompt)生成图像,或者是可以输入视频然后通过文本的形式回答问题。
2、AnthropicAI公司的Claude将发布。为了更好地理解 Transformer 的工作原理,Anthropic 研究人员简化了架构,去掉了所有的神经元层和除一层或两层注意力头之外的所有层。这让他们发现了 Transformer 和他们完全理解的更简单模型之间的联系。Claude的发布,将人工智能算法变得更加透明,可解释性。
3、DeepMind将发布Sparrow。Alphabet旗下的DeepMind推出了人工智能驱动的聊天机器人Sparrow,被称为该行业努力开发更安全的机器学习系统的里程碑。据DeepMind称,与早期的神经网络相比,Sparrow可以更频繁地对用户的问题给出合理的答案。此外,这款聊天机器人还包括一些功能,可以显著降低偏见和有毒答案的风险。DeepMind希望它用于构建Sparrow的方法将促进更安全的人工智能系统的开发。DeepMind的研究人员使用一种被称为强化学习的流行人工智能训练方法开发了Sparrow。该方法包括让一个神经网络重复执行一个任务,直到它学会正确地执行任务。通过反复的试错,网络可以找到提高精确度的方法。在开发Sparrow聊天机器人时,DeepMind将强化学习与用户反馈结合起来。Alphabet部门让一组用户向Sparrow提问,以评估该聊天机器人的准确性。该聊天机器人为每个问题生成多个答案,用户选择他们认为最准确的答案。
相信,Sparrow将是chatGPT的强大竞争对手,二者将一争高下。
4、从文本到视频的到来。2022年最热的是text-to-image diffusion model,基于文本作画。目前三大算法Disco Difusion、AI Art Machine,DALL-E正在一争高下。Disco Difusion原理是使用了CLIP-Guided Diffusion,从而让你可以仅仅通过文字输入,就能让AI产生相应的输出。AI Art Machine也是类似原理。而DALL-E是OpenAI的多模态预训练模型,从文本到图像的生成上,效果也很好。DALL-E通过120亿参数的模型,在2.5亿图像文本对上训练完成。
2023年则更进一步,通过语言文本就能生成视频。这将让视频的制作成本极大的降低。事实上,目前AI已经能将以前不是高清的视频高清化,也能补桢。今年可能是直接生成视频。梅斯医学认为,这一技术的实现,将极大推动元宇宙的发展。事实上,元宇宙最大的障碍就是视频生成(虚拟场景的生成)。
5、StabilityAI要来了。Stability AI 宣布发布 Stable Diffusion,Stability AI 成立于 2020 年,旨在培育开源 AI 研究社区。此次开源的 Stable Diffusion 是 Stability AI、RunwayML、LMU Munich、EleutherAI 和 LAION 等知名 AI 实验室的研究人员合作的结果。Stable Diffusion 是一个类似 DALL-E 2 的系统,可以从文本描述生成对应的图像。
6、Google发起「红色代码警戒」(Code red)。由于ChatGPT横空出世,Google 似乎已经将 ChatGPT 视为威胁,甚至其在内部为此拉起了一道「红色代码警戒」(Code red),担心这款产品将对 Google 搜索引擎的未来带来巨大挑战。
7、Blake Lemoine可能是对的。
Blake Lemoine在谷歌工作了7年,之前主要研究主动搜索,其中包括个性化算法和人工智能。他的主要工作是和谷歌研发的AI聊天机器人LaMDA对话,检查它会不会使用歧视性或仇恨性语言。LaMDA是“对话应用语言模型”的简称,它从互联网摄取数万亿的词汇来模仿人类对话,是谷歌基于其最先进的大型语言模型构建聊天机器人的系统。Blake Lemoine跟LaMDA聊着聊着竟然聊出了感情,认为人工智能具有意识。随后谷歌以“违反保密协议”为由将其停职。
也许,人工智能真的能进化出意识!
当然,除了上述内容外,梅斯医学认为,还需要关注人工智能在细分垂直领域的进展。
1、期待DeepMind新的突破
就象deepmind在围棋领域的AlphaGo,编程领域的alphaCode,蛋白结构预测的AlphaFolder,矩阵算法的AlphaTensor,每一个都石破天惊!!同时,DeepMind团队用AI帮助发现了一种处理表象理论(representation theory)中长期猜想的新方法。在拓扑学中发现了一个新定理等等。那么2023年,DeepMind团队还有哪些石破天惊的突破呢?而且这些突破往往都是原始性创始!
也许有一天DeepMind团队获得诺贝尔奖也不为过!事实上,2022年9月23日,引人注目的科学突破奖就给了开发了准确预测蛋白质结构的AlphaFold的Demis Hassabis和John Jumper!
2、训练大型语言模型将逐渐开始耗尽数据
DeepMind的Chinchilla work等研究已经表明,构建大型语言模型(LLM)最有效的方式不是把它们做得更大,而是在更多的数据上对其进行训练。
但是世界上有多少语言数据呢?更准确地说有多少语言数据达到了可以用来训练语言模型的要求呢?实际上,现在网络上大多数的文本数据并没有达到要求,不能用来训练大型语言模型。
对于这个问题,我们很难给出确切的答案,但是根据一个研究小组给出的数据*,全球高质量文本数据的总存量在4.6万亿到17.2万亿个token之间。这包括了世界上所有的书籍、科学论文、新闻文章、维基百科、公开代码以及网络上经过筛选的达标数据,例如网页、博客和社交媒体。
DeepMind的Chinchilla模型是在1.4万亿个token上训练的。也就是说,在这个数量级内,我们很有可能耗尽世界上所有有用的语言训练数据。这可能成为人工智能语言模型领域持续进步的一大障碍。许多前沿AI研究人员和企业家私下里都对此忧心忡忡。
随着研究人员开始寻求解决数据短缺这一迫在眉睫的问题,预计2023年对这方面的关注度会增加。针对这一问题,合成数据是一种可能的解决方案,尽管该如何操作这一方法还未可知。还有另一种可能的方法,那就是系统性地转录会议上的讲话,毕竟口头交流代表着还有大量未捕获的文本数据。
作为世界领先的LLM研究机构,人们十分好奇OpenAI在其即将发布的GPT-4研究中会如何应对这一挑战,同时,大家也期待着可以获得一些启发。
当然,也许会有更新的算法问世,解决数据被耗尽的难题
3、搜索重构,尤其是视频搜索
在ChatGPT出现之后,重新定义搜索的对话式搜索(conversational search)引起了人们的广泛注意。对话式搜索让我们可以与AI智能体进行动态对话以找到要查找的内容,不用再像传统的搜索引擎一样先输入要查询的内容,然后返回一长串链接,比如现在谷歌搜索的做法。
但这还不够,最关键的是视频搜索!
视频占据了互联网数据总量的80%左右,所以视频搜索代表了最大的发展机会。想象一下,如果我们可以轻松且准确地搜索视频中的某个片段、某个人、某个概念或者某个动作,这将是什么样的局面?Twelve Labs是一家初创公司,它构建了一个多模态AI平台,以实现精细化的视频搜索和理解。
4、人形机器人得到发展
人形机器人可能是好莱坞电影对AI进行夸张化的极端代表,比如说电影 《机械姬》和《我,机器人》。人形机器人发展迅速,并逐渐成为现实。
为什么要打造人形机器人呢?原因很简单,因为我们现实世界的大部分架构都是为了人类而打造,如果我们想利用机器人在工厂、购物中心、办公室和学校这样的场所自动完成复杂活动,最有效的方法就是让机器人拥有和人类一样的外形。这样,机器人就可以应用到多种场景中,且无需适应周围环境。
2022年9月,特斯拉在人工智能日推出了擎天柱(Optimus)机器人,这大大推动了人形机器人领域的发展。埃隆·马斯克表示,擎天柱最终会比汽车业务更有价值。然而,擎天柱机器人要想完全成熟,还任重而道远 。
5、人工智能助务药物研发,成为常态。
DeepMind于2021年7月开源了AIphaFold,并推出了一个数据库,它包含350,000种三维蛋白质结构(作为参考,在推出AlphaFold之前,人类已知的蛋白质结构大约有180,000种)。此外,几个月前,DeepMind公布了另一个包含2亿种蛋白质结构的数据库——这几乎覆盖了所有科学上已知的蛋白质。
DeepMind最新版本发布短短几个月后,就有来自190多个国家的50多万名研究人员使用AlphaFold平台,用它查看了200万种不同的蛋白质结构。但这仅仅只是开始。AlphaFold的巨大突破所带来的影响需要好几年才能逐渐展现出全貌。
到2023年,预计基于AlphaFold的研究数量将会激增。研究人员将利用这一庞大的新型基础生物学知识宝库,将其应用于新型疫苗、新型塑料研发等多个跨学科领域,进而改变世界。
6、通用机器人获得突破
人工智能一直被认为只能干一件特定的事情。事实上,通用智能的研究一直没有停止!
通用智能的关键是基础模型,这是人工智能最新发展的关键驱动力。如今,基础模型非常强大。但无论是GPT-3这样的文本生成模型,还是Stable Diffusion这样的文本转图像模型,又或是Adept这样的计算机操作(computer actions)模型,均只能运用于数字领域。
AI系统在真实世界的应用随处可见,例如自动驾驶汽车、仓库机器人、无人机、人形机器人等等,但到目前为止,它们大多还未受到基础模型新范式的影响。
这种情况将在2023年发生变化。预计用于机器人的基础模型这一早期开创性工作,将由世界领先的人工智能研究机构DeepMind、Google Brain和OpenAI完成(尽管OpenAI去年退出了机器人研究)。
7、AIGC快速应用于各个行业
AIGC ,即人工智能生成内容,会迈向工具性、普适化和工业化的大应用时代。互联网上各类新闻,视频,绘画等都逐步转向AIGC。信息的生产过度容易,进一步带动信息爆炸!
人们对信息的获取方式将发生深刻变革!互联网上的信息产生太过容易,因此真伪,质量高低将难以区分。
参考资料:
人工智能ChatGPT和Flan-PaLM双双通过美国医生许可考试(USMLE)
Nature:AlphaZero加强版AlphaTensor问世,发现史上最快矩阵乘法算法,在医学上能做什么?
2023年医疗健康十大科技发展趋势预测
人工智能相关话题,欢迎参与讨论
Nature:人工智能AI预测癌症起源,改善复杂转移性癌症的诊断
同期两篇Science | 人工智能革新蛋白质设计:准确而快速地创造蛋白质
Meta公司发布ESMFold,两周完成6亿+宏基因组蛋白质结构图谱
Nature:生命科学的变革:DeepMind人工智能可以预测大量蛋白质的结构
AlphaFold遇到有力竞争对手,Facebook打造的Meta AI更高效、更智能
聊天机器人ChatGPT出圈,能在医学领域干点啥?#黑科技#
人工智能,正在一步步逼近“真人类”,医疗能够被改变吗?

